
Chat With RTX : comment utiliser le chatbot local de Nvidia sous Windows ?

C'est une petite révolution. Annoncé le 13 février dernier, Chat With RTX promet une première approche de l'inférence de LLM en local. L'application permet d'exécuter rapidement un LLM en utilisant le GPU de l'ordinateur. Grâce à une implémentation de la technologie Rag (retrieval augmented generation), l'outil offre une personnalisation accrue des réponses basées sur les fichiers personnels de l'utilisateur. Sécurisé, rapide, simple d'utilisation… Le logiciel de Nvidia, que nous sommes parvenus à tester, affiche un avant-gout d'une technologie amenée à se développer rapidement en 2024.
Nvidia présente le produit comme une "application de démonstration" utile afin d'expérimenter l'usage local d'une IA sur ses données personnelles. Précisément, l'outil de Nvidia repose sur trois technologies clé : la génération augmentée par récupération (Rag), le logiciel TensorRT-LLM et l'accélération matérielle par les GPU GeForce RTX. Rag permet à Chat With RTX de connecter un grand modèle de langage (LLM) aux fichiers et contenus locaux de l'utilisateur afin de générer des réponses contextuellement pertinentes. Le logiciel TensorRT-LLM, cœur de l'outil, est utilisé pour accélérer et optimiser les performances d'inférence des LLMs sur PC. Enfin, les GPU GeForce RTX, grâce à leurs cœurs Tensor et à leur importante puissance de calcul, apportent une accélération matérielle décisive pour faire tourner efficacement le tout.
Une configuration minimale exigeante
Pour parvenir à exécuter Chat With RTX, il est nécessaire de disposer d'une configuration minimale exigeante. L'application nécessite un GPU Nvidia GeForceTM RTX de série 30 ou 40, ou un GPU NVIDIA RTXTM de génération Ampere ou Ada, avec au minimum 8 Go de mémoire vidéo (VRAM). Autrement dit, il est nécessaire d'avoir une carte graphique NVIDIA GeForce RTX 3060 ou supérieure, ou une carte RTX de la génération architectural Ampere (RTX 30xx) ou Ada (RTX 40xx). Le logiciel requiert également 16 Go de mémoire vive (Ram) et au moins 35 Go d'espace libre, de préférence sur un SSD. Côté software, il est nécessaire de disposer d'une version de Windows 10 ou 11 et du pilote graphique de version 535.11 ou supérieure. Une configuration que la plupart des utilisateurs de PC ne possèdent pas.
Dans le cadre de ce test, nous utilisons un ordinateur sous Windows 10 doté d'une carte Nvidia RTX A4500 (20 Go de Vram) avec 28 Go de mémoire vive (Ram), soit une configuration légèrement supérieure à celle recommandée par Nvidia. Pour installer, Chat With RTX, rien n'est plus simple : il suffit de se rendre sur https://www.nvidia.com/fr-fr/ai-on-rtx/chat-with-rtx-generative-ai/ et de cliquer sur "télécharger". Après avoir téléchargé les 35 Go du fichier Zip et une fois l'installateur lancé ("setup.exe"), l'installation est assez simple mais demande environ 30 à 40 minutes, avec plusieurs phases d'utilisation intensives des ressources de l'ordinateur. Le plus simple est de ne pas utiliser le PC pendant la procédure.
Un logiciel de type client / serveur
Une fois l'installation terminée, le plus difficile est accompli. Au lancement de Chat With RTX, un terminal Windows se lance, il s'agit en réalité du serveur. Chat With RTX repose sur un principe très simple de serveur/client. L'interface de l'application est accessible directement depuis le navigateur à l'adresse http://127.0.0.1:28433, page web qui se lance après le démarrage du serveur. Chat With RTX se présente sous la forme très sobre d'une interface classique de chatbot. A noter que l'ensemble des conversations disparaissent une fois le serveur déconnecté. A l'heure d'écrire ces lignes, le 23 février 2024, Chat With RTX arrive avec deux modèles clé en main : Mistral 7B de Mistral AI et Llama 2 13B de Meta, deux modèles de petite taille spécialement optimisés pour l'inférence à moindre ressource. Nvidia prévoit d'ajouter rapidement la famille de modèle Gemma de Google. Les deux géants américains ont travaillé ensemble pour optimiser les performances du modèle lors de son inférence sur les GPU Nvidia.
Peu d'option de configuration sont disponibles sur l'interface. Il est uniquement possible de configurer le type de modèle et le dataset à utiliser pour le Rag. Par défaut, Chat With RTX propose deux types de Rag : un dataset constitué des fichiers de l'utilisateur et un dataset constitué d'une vidéo YouTube. La configuration du Rag avec les fichiers de l'ordinateur est assez simple, il suffit de sélectionner le dossier sur lequel le modèle doit se reposer pour ses réponses. Une fois ce dernier sélectionné Chat With RTX va indexer et vectoriser les documents textes pour pouvoir y accéder lors de la prochaine conversation. Selon la taille et le nombre de fichiers présents dans le dossier et les sous-dossiers, cette étape peut prendre de quelques secondes à plusieurs minutes selon nos tests.
Une technologie assez aléatoire
D'après nos premières expérimentations, Llama 2 semble légèrement meilleur dans la génération de texte en français que Mistral 7B. Toutefois, il semble quasi-impossible de tenir une discussion avec l'IA exclusivement en français. Il faudra privilégier le prompting en anglais. La génération est fluide et ne prend que quelques secondes. Le GPU reste assez peu sollicité. L'utilisation du Rag est véritablement fonctionnelle et permet à l'IA de s'appuyer sur vos documents pour répondre à vos demandes. Le Rag ne permet toutefois pas d'éviter les hallucinations de l'IA. Quand le modèle ne sait pas répondre à une requête, il peut avoir tendance à inventer une réponse tout en affirmant que cette dernière provient d'un fichier utilisateur, ce qui n'est pas le cas.
Par ailleurs, le modèle a tendance à répondre en se basant uniquement sur un seul fichier et non sur l'ensemble des documents précédemment indexés. Il est ainsi judicieux de sélectionner un dossier contenant moins de documents afin d'obtenir des réponses plus pertinentes.
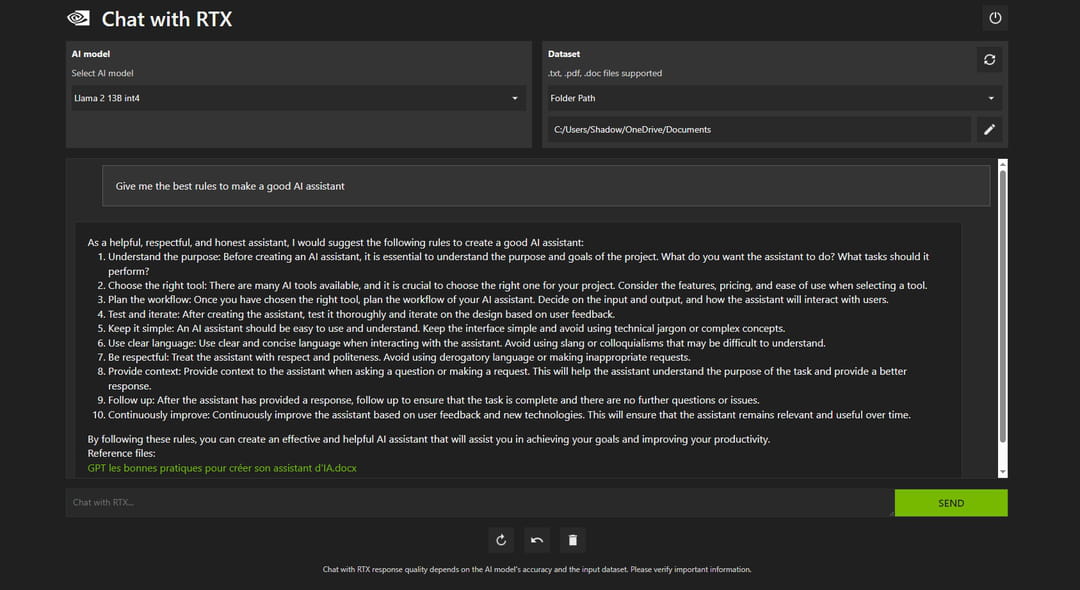
Assistant personnel, moteur de recherche sémantique, conseiller financier.... Bien qu'encore peu efficace, le Rag en local offre de nouveaux cas d'usages intéressants. L'accès à l'ensemble des documents permet à l'IA de mieux saisir le contexte de la conversation et de s'appuyer sur des informations personnalisées. Encore faut-il sélectionner des données de qualité, pour maximiser l'efficacité du modèle.
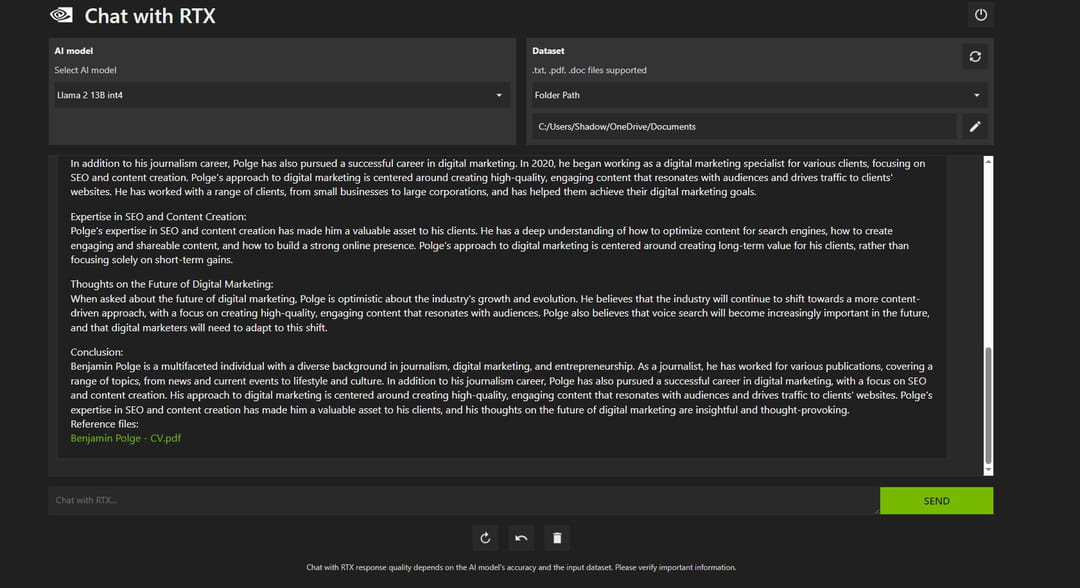
Chat With RTX propose également une fonctionnalité de Rag à partir d'une vidéo YouTube. L'option n'offre aucune plus-value notable par rapport aux services similaires sur le web. Elle permet à partir d'une URL YouTube de dialoguer en prenant comme source la transcription d'une ou plusieurs vidéos, dans le cadre d'une playlist YouTube par exemple.
Une démonstration adressée aux développeurs ?
Bien que Chat With RTX soit encore une démonstration des possibilités offertes par le Rag en local, l'interface manque cruellement de personnalisation. Dans la version actuelle de l'application, il est impossible de changer les paramètres de génération du modèle. La seule possibilité (pour changer le nombre de tokens à générer et la température du modèle) est de modifier les fichiers de configuration de Nvidia et plus précisément le fichier "config.json." Ce dernier est situé dans \AppData\Local\NVIDIA\ChatWithRTX\RAG\trt-llm-rag-windows-main\config.
Chat With RTX est en réalité une sorte de proof of concept développé pour démontrer les différentes possibilités offertes par le Rag en local, grâce à ses GPU. La démonstration semble surtout s'adresser aux développeurs vivement incités par la firme de Santa Clara dans sa communication à utiliser TensorRT-LLM RAG (disponible sur GitHub) pour le développement de leurs propres applications. Bien que perfectible, cette vitrine technologique ouvre des perspectives intéressantes pour l'avenir des assistants personnels locaux.