
Arctic, le LLM optimisé pour les entreprises à 480 milliards de paramètres de Snowflake

Une nouvelle ère glaciaire pour les LLM ? Snowflake présente ce 24 avril un nouveau LLM avec des performances proches de l'état de l'art open source. Constitué de 480 milliards de paramètres, Arctic est publié en sous-licence Apache 2. Ses performances et sa conception enterprise ready en font un modèle de choix pour les entreprises qui souhaitent basculer leur projet d'IA générative sur un modèle puissant et relativement efficace à l'inférence.
Un entraînement en trois phases
Arctic a été entraîné avec un budget minime de deux millions de dollars tout en offrant des performances remarquables. Le modèle est basé sur une architecture hybride Dense-MoE. Cette combinaison est dans la théorie plus efficace que l'architecture SMoE (Sparse Mixture of Experts) utilisée par Mistral AI pour Mixtral 8x7B et Mixtral 8x22B. L'apprentissage d'Arctic s'est déroulé en trois phases. La première, avec 1 000 milliards de tokens s'est concentrée sur les compétences génériques et de bon sens, avec pour objectif d'acquérir les capacités de base en compréhension du langage, raisonnement.
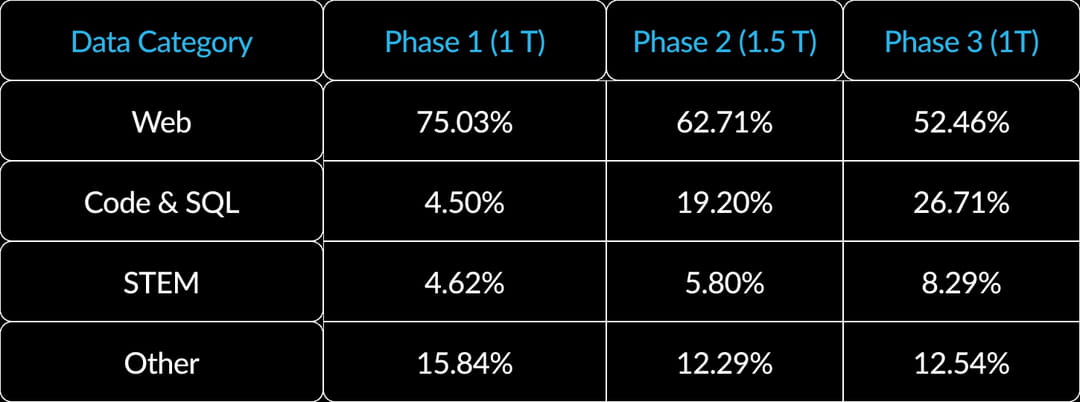
Dans un second temps, le modèle a été entraîné sur des données spécialement conçues pour lui "apprendre" des compétences inhérentes au monde de l'entreprise. L'accent est mis sur des tâches comme la génération de code, la génération de SQL et le suivi d'instructions avec un dataset de 1 500 milliards de tokens. L'objectif est de permettre au modèle d'exceller dans les domaines clés pour les cas d'utilisation d'entreprise. Enfin, le modèle a été entraîné sur la maitrise des compétences professionnelles complexes, avec 1 000 milliards de tokens supplémentaires. L'objectif est ici de permettre au modèle d'atteindre un niveau de performance exceptionnel sur les métriques d'intelligence d'entreprise.
Des performances solides qui rivalisent avec Llama 3
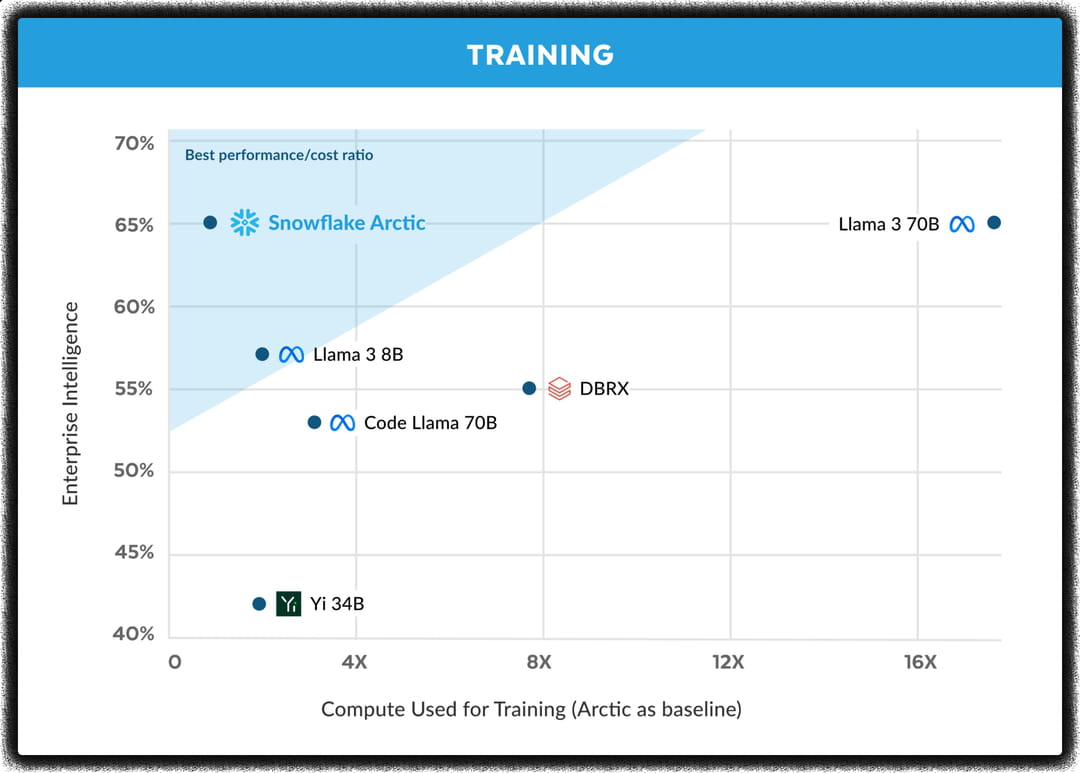
L'entrainement de Snowflake Arctic n'a pas été seulement sobre. Arctic rivalise avec les modèles open source les plus performants de sa catégorie, y compris le petit dernier de Meta Llama 3. Snowflake a véritablement optimisé son modèle pour qu'il soit efficient sur les tâches qui comptent pour les entreprises. Snowflake Arctic égale les autres modèles sur la génération de SQL (79%), la génération / compréhension de code (64,3%) et le suivi d'instructions (52,4%). Selon les tests menés par l'entreprise, Arctic est parfois aussi compétitif qu'un Llama 3 alors que son inférence exige moins de ressources matérielles.
Sur les métriques académiques comme les connaissances générales (MMLU) et le raisonnement, Arctic reste compétitif par rapport aux autres modèles, malgré un budget d'entraînement plus faible. DBRX et Llama 3 70B, obtiennent toutefois de meilleures performances au global.
Arctic est par exemple un excellent modèle pour la génération / compréhension de requêtes SQL, l'analyse de données professionnelles, la génération / compréhension de code. Il peut également être implanté au sein d'un système de chatbots grâce à sa faculté à suivre avec une précision fiable les instructions de l'utilisateur. Enfin, il peut être facilement fine-tuné pour performer davantage sur des tâches plus complexes.

Un modèle efficace à l'inférence
Arctic n'est pas seulement proche de l'état de l'art. Le modèle, de par son entraînement et son architecture innovante, est économe en ressources matérielles. Lors de l'inférence, seuls 17 milliards de paramètres sont activés (en théorie) sur les 480 milliards que compte le modèle. Pour l'inférence à faible débit (batch size de 1), Arctic nécessite jusqu'à 4 fois moins de lectures mémoire que des modèles plus volumineux comme CodeLlama 70B. Pour l'inférence à haut débit, Arctic nécessite également 4 fois moins de calcul que Llama 3 70B.
Snowflake travaille avec NVIDIA pour optimiser l'inférence d'Arctic, (quantification en FP8). Très concrètement, Arctic pourrait être déployé sur un seul GPU tout en assurant des performances d'inférence élevées et des pertes minimales d'accuracy. De manière générale, à paramètres égaux, Arctic sera plus efficace que DBRX, Llama 3 8B, Mixtral 8x7B ou code Llama 70B.

Un cluster de 8 H100 conseillé
En bref, Arctic offre de très bonnes performances pour une flopée de cas d'usage en entreprise. Du déploiement d'un chatbot, en passant par la génération de code ou le résumé de document, Arctic semble prometteur. Il peut être mis en place facilement et rapidement pour remplacer un modèle moins performant. Sa conception en fait également un modèle très efficace et économe, idéal pour réduire les dépenses matérielles.
L'équipe conseille un cluster de 8 H100 pour une inférence optimale. La seule limite reste sa taille de contexte relativement réduite de 4 096 tokens. Les équipes de Snowflake travaillent déjà sur une version dotée d'un contexte plus large. Arctic est accessible sur les plateformes habituelles, comme Hugging Face, les catalogues de modèles AWS, Azure, NVIDIA.