
Avec Music FX de Google, la génération de musique par IA fait un bond en avant

Le secteur musical sera-t-il le prochain à être disrupté par l'IA ? Stable Audio chez Stability AI, MusicGen chez Meta, Jukebox chez OpenAI… Les géants de l'IA dévoilent au fil des mois leurs dernières technologie en matière de génération de musique et traitement du son. Parallèlement à l'amélioration croissante des performances des grands modèles de langue, les modèles de génération de musique progressent à une vitesse toujours plus rapide. Dernière évolution majeure en date, l'ouverture au public de Music FX.
L'outil, développé par Google, permet de générer à partir d'une simple description textuelle une musique entièrement produite avec l'intelligence artificielle. Basé sur le modèle Music LM développé par DeepMind, l'outil a connu une mise à jour majeure début février 2024. A partir des retours utilisateurs (plus de 10 millions de pistes générées depuis le lancement), Google a amélioré sensiblement la qualité des musiques produites ainsi que le temps de génération. Nous avons pu tester la version déployée au 29 février. Cette dernière offre une qualité finale plutôt déconcertante.
Un dataset composé de 280 000 heures de musique
Dévoilé en 2023, Music LM est le fruit d'un développement de plusieurs mois chez DeepMind. Music LM est l'un des premiers modèle du domaine à apporter une musique de haute qualité (HiFi), cohérente sur la durée et d'une grande fidélité au prompt initial. Selon le papier de recherche publié par les équipes de DeepMind, Music LM utilise en réalité trois modèles pré-entraînés. D'abord SoundStream, un modèle de codage audio qui tokénise l'audio en discrete tokens (des tokens acoustiques). Chaque token capture une petite portion du signal audio. Ensuite W2v-BERT, un modèle de langage audio basé sur BERT (l'ancien modèle de langage de Google avant Gemini). Le modèle analyse l'audio et en extrait des "tokens sémantiques", qui captent la structure musicale et le sens général. Et enfin troisième modèle, MuLan, entraîné pour que les embeddings audio et texte se ressemblent lorsqu'ils correspondent au même contenu.
Une fois pré-entraînés, ces modèles sont assemblés dans MusicLM : SoundStream et w2v-BERT analysent les propriétés acoustiques et sémantiques de l'audio fourni en entrée, tandis que MuLan permet de conditionner la génération via du texte durant l'inférence. Concrètement, MusicLM est entraîné à prédire les suites de tokens sémantiques et acoustiques sur un vaste dataset musical, apprenant ainsi à synthétiser des extraits réalistes et cohérents sur le long terme. Pour l'entrainement du modèle, DeepMind s'est appuyé sur un immense dataset musical propriétaire d'une taille de 280 000 heures, soit approximativement 5 millions d'extraits audio à 24 kHz. Pour constituer ce corpus d'apprentissage, les chercheurs ont rassemblé toutes sortes de musiques avec un souci de diversité, allant du piano classique au jazz en passant par la techno.
La qualité au rendez-vous
Music FX, l'interface graphique de génération audio de Google, repose exclusivement sur le modèle Music LM. Il est possible que depuis la sortie du modèle en 2023 Google ait fine-tuné son modèle pour qu'il soit encore plus cohérent et riche de diversité musicale. L'outil, sobre, est très simple d'utilisation et permet à tout utilisateur de générer de petites compositions musicales très rapidement. Music FX demande simplement une description textuelle du style de musique attendu, en anglais. Selon nos tests, il n'est pas nécessaire d'avoir des prompt très longs pour obtenir un résultat satisfaisant. Le prompt idéal consiste en une brève description de la mélodie, des instruments à utiliser et du rythme général de la musique à générer.
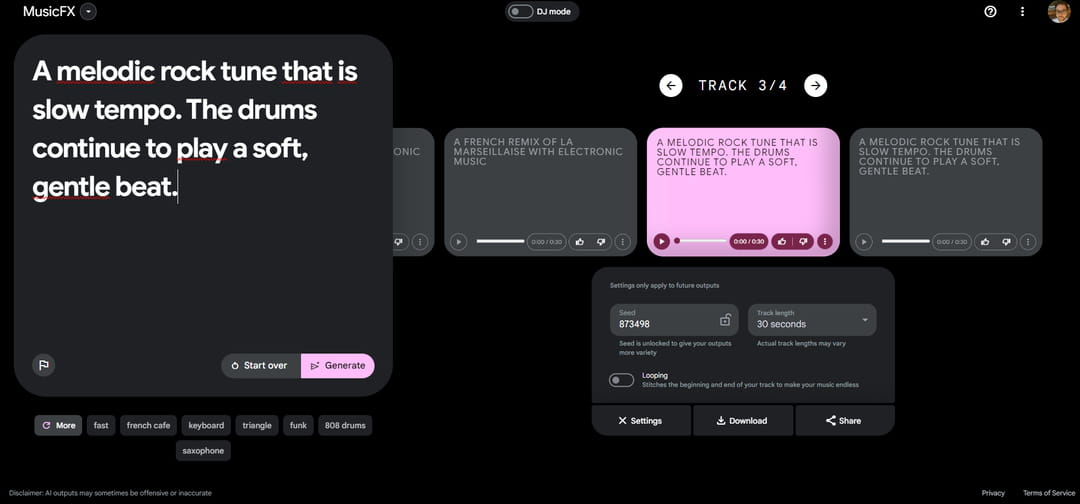
"A melodic rock tune that is slow tempo. The drums continue to play a soft, gentle beat" permet par exemple de produire une mélodie rock assez douce et harmonieuse rythmée par un tambour.
Contrairement aux précédents systèmes d'intelligence artificielle de génération audio, Music FX offre un son de bonne qualité avec une très bonne cohérence sur la longueur. Par défaut l'outil génère des pistes de 30 secondes mais il est possible d'augmenter la génération à 50 ou 70 secondes. Selon le temps sélectionné, la génération prend de quelques secondes à quelques dizaines de secondes. L'interface permet également de verrouiller le seed d'un titre généré pour produire une version plus longue de son premier titre sans changer les éléments principaux de la musique. En verrouillant le seed et en modifiant le prompt, il est aussi possible d'ajouter de nouveaux éléments musicaux en conservant la mélodie précédemment générée.
Music FX ne prend pas en charge la génération de voix synthétiques. Parallèlement, à cette limitation, l'outil ne permet pas non plus de reproduire le style d'un artiste ou d'une mélodie en particulier, même issue du domaine public. Pour exemple, il est impossible de générer une version remasterisée de la Marseillaise. Le prompt " La Marseillaise, the French national anthem in a rock version", produit une beau son rock qui n'a rien de commun avec la mélodie originale.
DJ mode : une démonstration prometteuse
C'est sans doute la fonctionnalité la plus épatante. Ajouté quelques semaines avant notre test par Google, DJ Mode de Music FX permet de générer en live de la musique, comme le ferait un véritable disc-jockey. L'outil offre la possibilité de jouer de la musique en utilisant jusqu'à 10 prompts à la fois. Chaque prompt doit préciser le style de musique, d'instrument, d'effet sonore ou même d'émotion à jouer. Comme sur une véritable table de mixage, chaque prompt constitue une entrée audio qu'il est possible d'augmenter ou de réduire afin de changer la composition actuellement jouée. Pour l'heure, les sessions de mix sont limitées à une heure et se coupe au bout de deux minutes si aucune action sur l'interface n'est détectée par le système.

L'outil, bien qu'encore en démonstration, offre une cohérence et une qualité sonore inégalées. Les transitions entre deux styles musicaux sont fluides et particulièrement cohérentes. Le changement d'intensité des prompts et l'ajout d'un nouvel élément ne prend que quelques secondes. Le résultat est bluffant. Seul regret, comme avec la génération classique dans Music FX, il est impossible de générer des voix.
Les possibilités offertes par Music FX sont particulièrement prometteuses. A terme, l'outil pourrait permettre à de nombreux créateurs, musiciens, producteurs ou DJs en herbe de générer rapidement des maquettes, des pistes d'ambiances sonores ou des transitions fluides entre deux styles musicaux sans devoir maîtriser un instrument ou des logiciels de MAO complexes.