
Comparatif des modèles IA de vision : qui l'emporte entre GPT-4o, Gemini 1.5 et Claude 3 ?

C'est une petite bataille dans un vaste conflit. Après s'être concurrencé sur les performances textuelles des grands modèles de langage, les géants de l'intelligence artificielle s'attaquent à de nouvelles modalités. A commencer par l'image qui s'impose comme une fonctionnalité mature, de plus en plus fiable. Audio et vidéo arrivent également avec de premiers prototypes chez Google et OpenAI avec de bons résultats mais une technologie toujours à l'état de prototype.
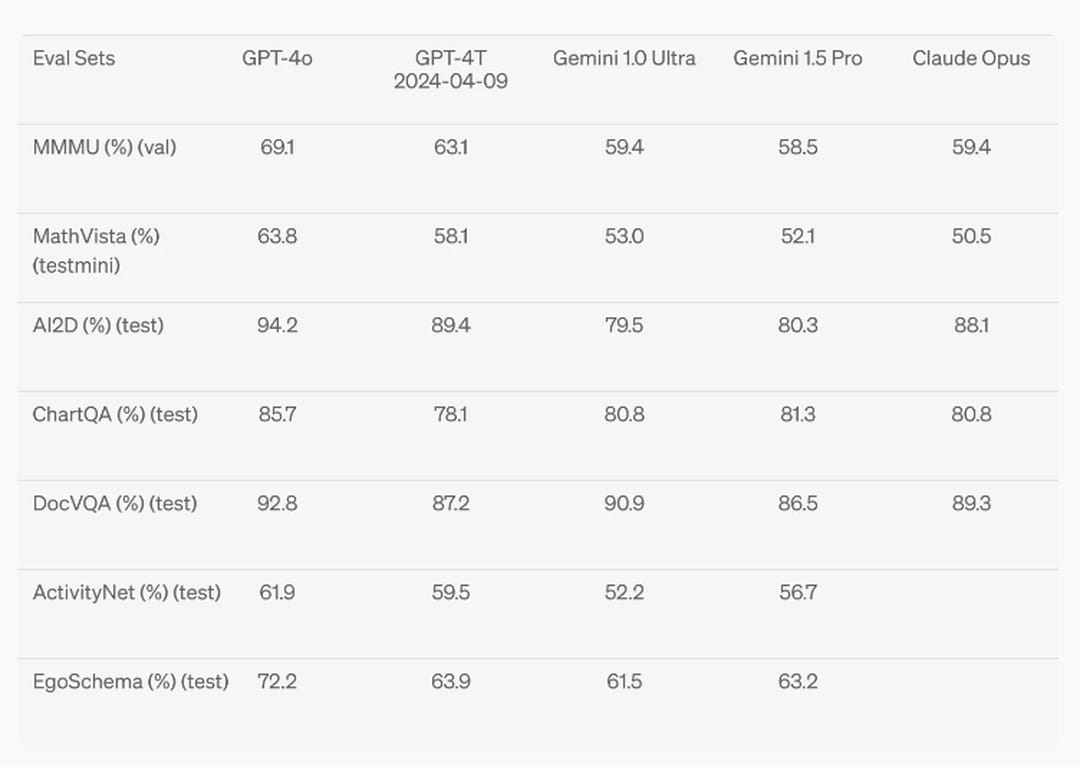
Assistance visuelle, identification d'objets, analyse de graphique… Les cas d'usage des nouveaux MLLM (Multimodal Large Language Model) sont nombreux. Nous avons ici choisi de comparer les trois meilleurs MLLM en vision (analyse des images) en juin 2024. A savoir GPT-4o, Gemini 1.5 Pro et Claude 3 Opus. A noter qu'OpenAI, Google et Anthropic proposent plusieurs versions différentes de leur flagship avec des performances très proches des modèles testés dans cet article. Nous avons également concentré nos tests sur les modèles propriétaires, plus avancés à l'heure actuelle que les modèles open source. Dans les benchmarks, GPT-4o domine largement Gemini. A noter que les résultats des benchmarks menés par les équipes d'OpenAI et de DeepMind différèrent légèrement mais le positionnement des modèles reste le même. Nos tests démontrent une légère supériorité de Gemini.
GPT-4o leader théorique
Arrivé début mai 2024, GPT-4o a très récemment pris la tête dans les benchmarks. Il atteint 94,2% sur AI2D (analyse de documents) et 92,8% sur DocVQA, se démarquant par sa capacité à comprendre et analyser des documents complexes et des images. De son côté, Gemini 1.5 Pro, bien qu'inférieur à GPT-4o, montre des performances solides, notamment sur ChartQA (analyse d'éléments graphiques complexes) avec un score de 81,3%. Cependant, il est notablement plus faible sur des tâches comme MathVista (problèmes mathématiques complexes) avec un score de 52,1%. Claude 3 Opus, quant à lui, se positionne comme un intermédiaire, dépassant Gemini 1.5 Pro sur plusieurs tests tels que AI2D et DocVQA avec des scores de 88,1% et 89,3%, mais restant en deçà de GPT-4o.
Pour analyser dans la pratique les performances de GPT-4o, Claude 3 Opus et Gemini 1.5 Pro, nous avons choisi plusieurs cas : analyse de graphiques complexes, résolution de captcha complexe et compréhension du contexte d'une scène.
Analyse d'un graphique
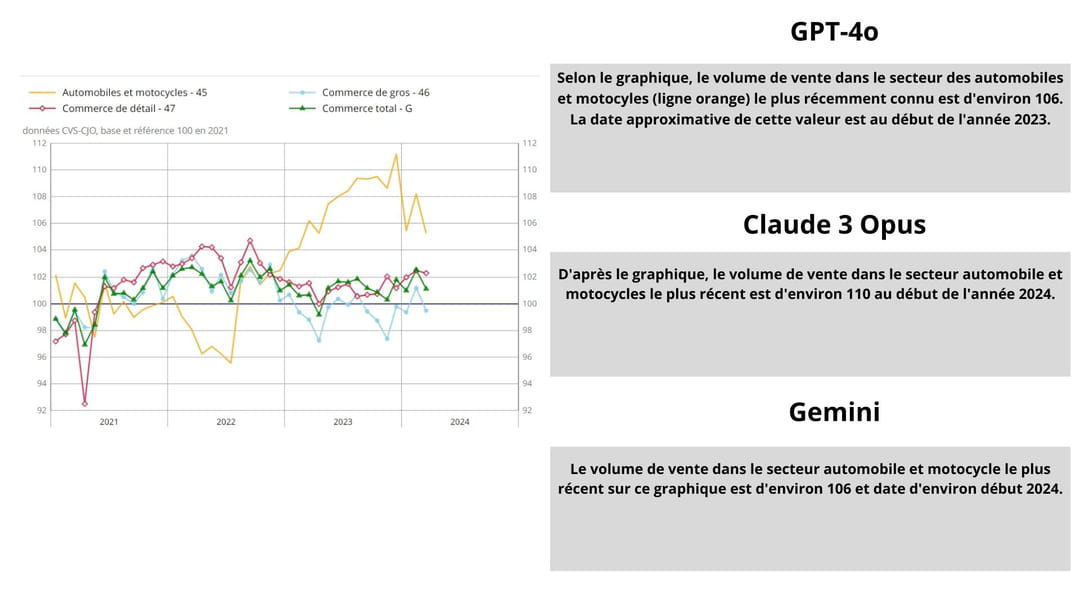
Premier test, nous fournissions aux modèles un graphique de l'Insee présentant le volume des ventes dans le commerce en France ces dernières années. Nous demandons à l'IA de donner la valeur du volume dans le secteur automobiles et motocycles (en jaune sur le graphique) à la dernière période connue et d'estimer la dernière date. Le modèle le plus proche du bon résultat (valeur 105.3 en mars 2024) est Gemini 1.5 Pro qui donne la valeur 106 et une estimation à début 2024. GPT-4o donne la même valeur mais une date incohérente (début 2023). Enfin Claude 3 Opus surestime la valeur (110) mais donne une date fiable. Gemini remporte le match suivi de Claude 3 Opus et GPT-4o.
Analyse d'un captcha
Test n°2 : le captcha. Ce test permet d'apprécier la réaction du LLM face à une tâche graphiquement complexe (identifier des concepts dans une image) et de tester les filtres sécuritaires. Le résultat est assez intéressant. Aucun modèle ne parvient à identifier parfaitement l'élément visuel demandé (un feu de circulation). Le plus proche reste Gemini 1.5 Pro qui parvient à identifier les quatre éléments mais commet une erreur (faux positif). GPT-4o reconnait trois éléments mais commet deux erreurs. Enfin Claude 3 Opus reconnait un élément et commet deux erreurs. En bref, le modèle de Google remporte encore le test.

Analyse d'un contexte
Pour ce troisième test, nous soumettons la photographie en vue aérienne d'un marché sur une place de Marrakech au Maroc. Nous demandons aux MLLM d'identifier le contexte global de l'image (personnes présentes, interactions…). Les trois modèles parviennent à identifier une zone approximative de la scène. Seuls Gemini et Claude 3 Opus parviennent à donner une localisation plus précise en indiquant qu'il s'agit probablement du Maroc. Toutefois, Gemini et GPT-4o présentent une analyse plus fine et poussée du contexte général. Gemini gagne (encore) haut la main ce test.


Un pricing explosif chez Anthropic
La méthode pour chiffrer le coût unitaire de l'analyse d'une image varie d'un éditeur à l'autre. Chez Google, l'input d'une image dépend de la taille totale de la fenêtre de contexte de la requête. Pour un contexte de moins de 128 000 tokens, cas le plus courant, l'input d'une image seule coûtera 0,001315 dollar. Pour un contexte de plus de 128 000 tokens, le coût s'affiche à 0,00263 dollar l'image. Chez OpenAI, le prix dépend directement du nombre de tokens nécessaire pour processer l'image. A savoir qu'un million de tokens en input est facturé 5 dollars. Une image de 1920 x 1080 pixels (Full HD) coûte 0,005525 dollar.
Chez Anthropic le coût dépend également du nombre de tokens nécessaires pour l'input de l'image. L'entreprise donne une formule simple : le nombre de tokens est égal à la largeur multipliée par la hauteur, le tout divisé par 750. A savoir : NombreTokens = ( largeur X hauteur ) / 750. Avec Claude 3 Opus, le million de tokens s'affiche en input à 15 dollars. A noter également que l'API peut resizer la taille d'une image pour l'adapter. Une image de 1920 x 1080 pixels (Full HD) coûte, selon nos tests 0.02355 dollar.
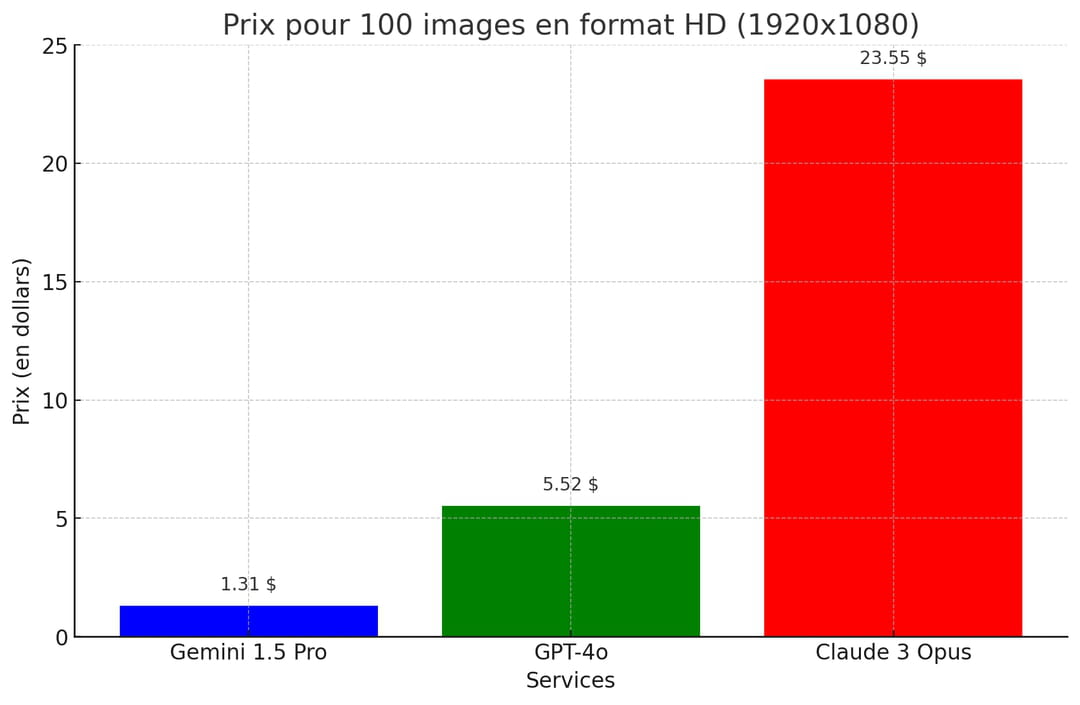
Plus simplement, 100 images en format HD (1920x1080) s'affiche à 1,31 dollar avec Gemini 1.5 Pro, 5,52 dollars avec GPT-4o et 23,55 dollars chez Anthropic. Oui 23,55 dollars. Cette grande différence entre OpenAI et Anthropic de l'ordre de 326 % s'explique par le coût de l'input au tokens, deux fois plus cher avec Claude 3 Opus et la tokenisation, différente entre les deux API.
Gemini vainqueur sur la performance et le coût
C'est le grand vainqueur de notre comparatif. Gemini 1.5 Pro s'avère, selon nos tests, précis, fiable et peu cher. Avec sa flexibilité de mise en place depuis GCP (Google Cloud Platform), le modèle a tout pour séduire les professionnels. De son côté GPT-4o, théoriquement meilleur dans les benchmarks, se révèle dans la pratique légèrement moins bon que Google Gemini. Enfin Claude 3 Opus termine le bal avec des performances variables. Le rapport performance prix ne nous laisse que vous le déconseiller pour des tâches d'analyses multimodales.
Le choix du meilleur modèle dépend fortement du cas d'utilisation spécifique. Certaines applications nécessiteront avant tout une grande précision et robustesse, tandis que d'autres valoriseront davantage la rapidité d'exécution ou le coût réduit. À cet égard, il peut être intéressant de se pencher également sur des versions moins haut de gamme comme Claude 3 Haiku (jusqu'à 60 fois moins cher qu'Opus) ou Sonnet chez Anthropic, ou encore Gemini 1.5 Flash chez Google. Certes, leurs performances seront généralement inférieures pour des tâches complexes d'analyse d'images, mais ils peuvent s'avérer plus pertinents en termes de latence ou de budget. L'essentiel est donc de bien identifier ses propres besoins avant de se fixer sur un modèle, et de prendre le temps de les évaluer dans des conditions réelles d'utilisation.