
Souveraineté par données : Apache Iceberg, le format de table universel
L'adoption des nouvelles technologies ne suffit pas à elle seule pour assurer une transformation numérique de l'organisation. Elle doit penser sa stratégie à l'aune du numérique.
En 20 ans les organisations ont dû faire face à un nombre de changements permanents : Internet, le collaboratif, le cloud, les réseaux sociaux, le mobile, le big data, le machine learning… Le COVID. Aujourd'hui l’Intelligence artificielle générative ! Et demain ?
L’adoption des nouvelles technologies ne suffit pas à elle seule pour assurer une transformation numérique de l’organisation. Elle doit penser sa stratégie à l’aune du numérique.
Il peut déjà être noté ici, qu’il n’y a pas de transformation numérique sans données.
La transformation numérique des organisations passe aussi par la mise en données de leurs activités. Tout événement est mesuré. La consolidation des observations facilite une prise de décision éclairée.
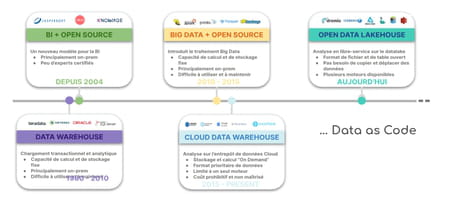
Nombreuses sont les organisations ayant mis en œuvre des flux ETL, des plates-formes de reporting, de la data visualisation ou carrément des processus de machine learning. Néanmoins, les projets de business intelligence ne précèdent jamais les projets SI ou les projets de mise en place de tels ou tels logiciels. Les données issues des systèmes transactionnels n’ont malheureusement pas toutes les composantes utiles aux analyses attendues par les équipes métiers.
Comme peu d’organisations pensent l’analytique dès la conception des solutions, on observe de nombreuses irritations dans le cadre des constructions de flux de transformation de données. Les solutions contemporaines de gestion de données sont peu productives et incitent à une grande prolifération des données, une grande prolifération des mêmes jeux de données.
Or, les entreprises sont confrontées à de nombreuses turbulences, elles doivent de plus en plus souvent s'adapter. Ce qui signifie gérer des données qui évoluent, des schémas de données qui bougent en même temps que les demandes des utilisateurs se façonnent.
Déconstruire la base de données pour mieux l’appréhender et servir les nouvelles stratégies des organisations.
Bien sûr, la transformation numérique des organisations va de pair avec les données, leur quantité, leur variété. Les bases de données classiques ont été bousculées tant du point de vue des données non structurées que pour leur incapacité à passer à l’échelle. En même temps, si Hadoop était apparu comme un cadre pour exécuter tout type de traitements, il n’a pas su être autant agile que ne l’est aujourd’hui le data lakehouse. Cette architecture offre l’ouverture et la flexibilité, du data lake, et la rigueur et la structuration du data warehouse.
A toutes les époques, les organisations ont eu besoin de consolider leurs données. Aujourd’hui plus que jamais, les données, bien structurées, valent effectivement de l’or, tant elles viennent servir à nourrir et entraîner des larges languages models s’il n’y avait que cet exemple à donner !
Adopter Apache Iceberg !
Est-ce que quelqu’un connaît le nom du format de tables de la base de données d’Oracle ? Non ! Ou encore celui de MySQL… Un peu plus : Innodb, MyIsam…
Pour l’analytique, l’industrie a fait le choix d’Apache Iceberg.
Apache Iceberg, a été développé à l’origine chez Netflix. Il vise alors à résoudre des difficultés que rencontrent les ingénieurs de données avec le data warehouse Apache Hive.
Apache Iceberg est un format de table open source conçu pour gérer de large tables pouvant stocker des pétaoctets de données. Un format table a pour but de structurer, coordonner et tracer l’ensemble des fichiers qui hébergent les données et les métadonnées de la table. Vous pouvez voir le format table telle une couche d’abstraction entre les fichiers physiques (écrits en Parquet) et la représentation que l’on se fait d’une table de données (structuration tabulaire).
Avant même d’étayer les caractéristiques de ce format de table, arrêtons-nous sur tous ceux qui l'ont déjà adopté. En 2019, nous assistons à une présentation client avec l’éditeur Dremio, à toutes les questions qui peuvent être posées, Tomer Shiran, actuel CPO, répondait “ce sera pris en charge avec Apache Iceberg” ! Le projet à ce moment-là est encore très jeune et très peu adopté !
Aujourd’hui, Netflix, Apple, AWS, Google Big Query, Snowflake, Salesforce, OVH Cloud, Cloudera, Tabular, Dremio, Teradata, Starburst, Confluent… LinkedIn, Stripe, Tencent, Alibaba… ont déjà fait le choix d’Apache Iceberg. Bien sûr que Apache Iceberg fait face à des formats de table concurrents ; Les acteurs qui l’ont choisi sont très nombreux et représentent une très large part du marché. De même, l’écosystème des contributeurs est très équilibré.
Tomer Shiran avait donc vu juste ! Apache Iceberg, fort de ces nombreuses caractéristiques techniques, socle désormais une nouvelle architecture pour gérer les données : le data lakehouse.
Pourquoi Apache Iceberg ?
- Le langage SQL : C’est un langage mûr ! Qui évolue encore. Il est intégré aux nombreuses autres langages de programmation. Il correspond à l’interface principale des solutions de business intelligence et d’analyses avancées.
- Cohérence des données : Dès sa conception Apache Iceberg intègre les propriétés ACID afin de garantir que tous les utilisateurs qui lisent et écrivent sur les données voient les mêmes données.
- Évolution des schémas : quand bien même les données sont stockées à même un lac de données, Apache Iceberge gère parfaitement les structures de données qui évoluent. Il est simple et aisé de procéder à des modifications de structures de données. Ce qui signifie que les utilisateurs peuvent ajouter, renommer ou supprimer des colonnes d'une table de données sans perturber les données sous-jacentes.
- Version des données : Apache Iceberg enregistre toutes les modifications que subissent les données. Ainsi, les utilisateurs peuvent les suivre au fil du temps. La fonctionnalité porte d’ailleurs le nom de voyage dans le temps (en anglais Time Travel). L’utilisateur peut accéder à l’historique d’une table et l’interroger.
- Support multiplateforme : Apache Iceberg prend en charge les stockage de Google Cloud, d’AWS, d’Azure, d’Hadoop, Minio, CEPH, OVH Cloud High Perf, (ou tout stockage compatible S3). Il peut être interrogé depuis Apache Spark, Apache Flink, Apache Hive, Presto, Dremio, Duckdb, Java, Python, Rust…
- Traitement en continu : Apache Iceberg sait recevoir des données issues d’un traitement en continu ! Une telle pratique génère de très nombreux petits fichiers ! Mais Apache Iceberg fournit intrinsèquement les outils nécessaires pour optimiser les tables et conserver des temps de réponses performants. Cette caractéristique va grandement être améliorée dans les prochains mois grâce au Merge on Read.
Apache Iceberg, le format standard pour la transformation numérique.
Le support de la transformation numérique a beaucoup été le cloud. Plus récemment, ce sont les data warehouse dans le cloud qui sont devenus le cœur des données des organisations. Ces architectures sont coûteuses et “ceinturent” l’organisation chez son fournisseur. Elles n’offrent pas toujours l’agilité nécessaire pour rapidement délivrer les données attendues par les métiers.
Apache Iceberg évite le “vendor locking” ! Dit autrement, Apache Iceberg offre une reprise en main de la souveraineté. Cette fois-ci, il s’agit de la souveraineté par les données ! Le caractère ouvert d’Apache Iceberg, l’accès multiplateforme apportent aux DSI une nouvelle gestion de données plus durable.
Fort de ses niveaux de compression de données, fort de toutes ses métadonnées, ce format de table facilite les réductions de coûts de stockages. Il en va de même pour les coûts d’usage car moins de données sont balayées durant les interrogations.
Apache Iceberg n’a pas fini de nous dévoiler tous ses atouts.
Un des cas d’usage qui va faire date et qui va transformer la manière dont les organisations exploitent les données, c’est celui de Salesforce. Grâce à Apache Iceberg les clients de Salesforce vont directement pouvoir interroger leur données, en toute sécurité et ce sans avoir à la recopier ! Toutes les organisations échangent des données ! Et ces données sont tellement souvent copiées ! Sur le modèle de Salesforce les organisations pourraient enfin partager des données et non des fichiers ! Une véritable rationalisation du partage des données est en œuvre. Avec un vrai impact de la gouvernance des données. Un jeu de données peut tout aussi bien être utilisé par les utilisateurs internes que par les partenaires, les règles de sécurité étant bien gérées.
En poursuivant la réflexion du point de vue du partage de données… Apache Iceberg apporte aussi une vision renouvelée du catalogue de données ! Justement, les organisations doivent nécessairement chercher à avoir un point d’accès unique à toutes leurs données ! La régulation les oblige.
La toute première conférence d’Apache Iceberg a eu lieu les 14 et 15 mai 2024 (https://iceberg-summit.org/). Cette volonté des contributeurs de l’organiser marque un changement de cap pour ce projet qui comprend qu’il est en passe de devenir un format de table universel pour la analytique.